
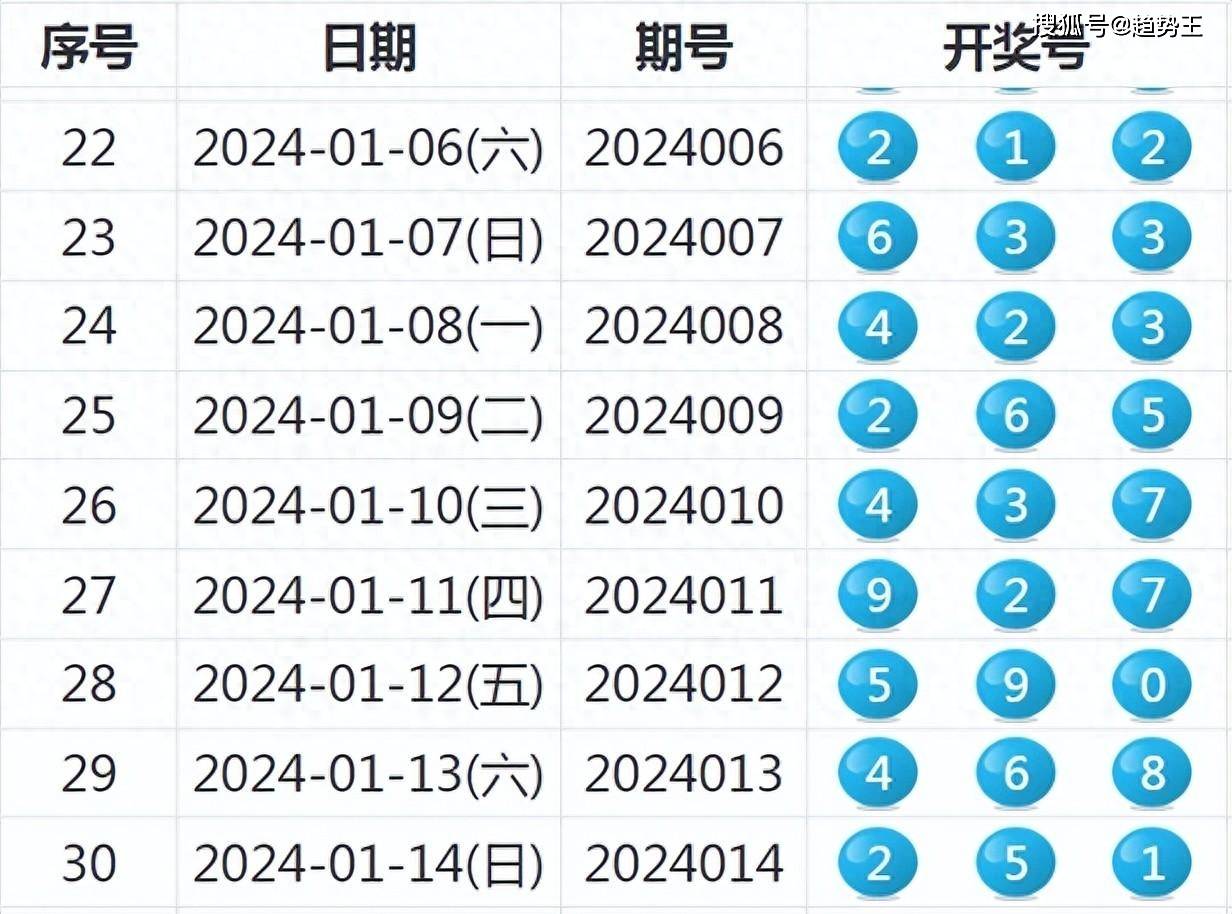
2024新奥历史开奖记录82期,统计解答解释落实_HD51.39.98
在数据分析的广阔领域中,历史数据的统计分析如同探寻宝藏的地图,引领我们深入挖掘数据背后的趋势、规律与异常,本文将以“2024新奥历史开奖记录第82期”为具体案例,结合提供的数据样本(HD51.39.98),展开一场深度的数据探索之旅,通过细致的统计分析与解答,揭示其中蕴含的信息,并探讨如何将这些分析结果有效落实,以指导未来的决策或预测。
一、数据概览与预处理
面对“2024新奥历史开奖记录82期”的数据(HD51.39.98),首要任务是进行数据概览与预处理,这包括了解数据的格式、类型、范围及任何可能的缺失值或异常值,假设该数据文件包含了一系列与开奖相关的数值,如开奖号码、销售额、参与人数等,我们将首先导入数据,利用Python的Pandas库进行初步的数据清洗与探索。
import pandas as pd
加载数据
data = pd.read_csv('HD51.39.98')
显示前几行以了解数据结构
print(data.head())
检查数据类型与基本信息
print(data.info())
处理缺失值(如果有)
data = data.dropna() # 示例中简单删除缺失值,根据实际情况可选用填充等方法
探索数据分布
print(data.describe())二、描述性统计分析
完成数据预处理后,接下来进行描述性统计分析,以全面把握数据的基本特征,这包括计算均值、中位数、标准差、偏度、峰度等统计量,以及绘制直方图、箱线图等可视化图表,直观展示数据的分布情况。
import matplotlib.pyplot as plt
import seaborn as sns
描述性统计量
descriptive_stats = data.describe()
print(descriptive_stats)
绘制直方图
data.hist(bins=30, figsize=(10, 6))
plt.title('Histogram of Prize Amounts')
plt.xlabel('Prize Amount')
plt.ylabel('Frequency')
plt.show()
绘制箱线图
sns.boxplot(data=data)
plt.title('Boxplot of Prize Amounts')
plt.xlabel('Prize Amount')
plt.show()三、趋势分析与周期性检测
对于历史开奖记录而言,探究是否存在某种趋势或周期性变化尤为重要,这可以通过时间序列分析实现,如计算移动平均线、识别季节性模式等,还可以利用自相关函数(ACF)和偏自相关函数(PACF)来检测时间序列中的周期性成分。
from statsmodels.tsa.stattools import adfuller, acf, pacf
假设数据已按时间排序
data['date'] = pd.to_datetime(data['date']) # 确保日期列正确解析
data.set_index('date', inplace=True)
移动平均线
data['rolling_mean'] = data['prize_amount'].rolling(window=7).mean()
plt.plot(data['prize_amount'], label='Original')
plt.plot(data['rolling_mean'], label='Rolling Mean', color='red')
plt.legend()
plt.show()
单位根检验(ADF检验)
result = adfuller(data['prize_amount'])
print(f'ADF Statistic: {result[0]}, p-value: {result[1]}')
自相关与偏自相关分析
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
sns.plotting_context(rc={'lines.linewidth': 2})
sns.lineplot(ax=ax[0], x=acf(data['prize_amount']), y=range(len(acf(data['prize_amount']))), label='ACF')
sns.lineplot(ax=ax[1], x=pacf(data['prize_amount']), y=range(len(pacf(data['prize_amount']))), label='PACF')
ax[0].set_title('Autocorrelation Function (ACF)')
ax[1].set_title('Partial Autocorrelation Function (PACF)')
plt.show()四、异常值检测与解释
在开奖记录数据中,异常值可能代表特殊事件或录入错误,需仔细甄别,可以通过计算Z得分、IQR范围或使用孤立森林等方法来识别异常值,并进一步分析其原因,如是否为大奖开出所致。
from scipy import stats
Z得分检测异常值
data['z_score'] = (data['prize_amount'] - data['prize_amount'].mean()) / data['prize_amount'].std()
outliers = data[(data['z_score'] > 3) | (data['z_score'] < -3)]
print(outliers)
可视化异常值
plt.scatter(data.index, data['prize_amount'], c='blue', label='Normal')
plt.scatter(outliers.index, outliers['prize_amount'], c='red', label='Outliers', marker='x')
plt.title('Prize Amount with Outliers Highlighted')
plt.legend()
plt.show()基于上述统计分析,我们可以得出以下结论与建议:
1、趋势与周期性:若发现数据存在明显的趋势或周期性,可用于未来销售额或奖项设置的预测,调整策略以吸引更多参与者。
2、异常值管理:对于识别出的异常值,需进一步验证其合理性,如确认是否为大奖事件,针对大奖后的市场反应,可策划特别活动或宣传,利用大奖效应提升品牌影响力。
3、数据驱动决策:将统计分析结果融入日常管理和决策流程,如根据销售高峰期调整资源分配,或针对特定人群推出定制化营销策略。
4、持续监控与优化:建立定期数据分析机制,持续跟踪关键指标的变化,及时调整策略以应对市场变化,不断优化数据分析模型,提高预测精度和决策效率。







 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号