
新澳2024年精准特马资料分析与预测
前言
随着赛马运动的普及和博彩业的发展,越来越多的爱好者和投资者开始关注赛马比赛的结果,本文将基于历史数据和新澳2024年的赛事安排,运用数据分析方法,对新澳2024年的特马进行详细解答和预测,本文旨在为读者提供一种科学、合理的参考依据,帮助大家更好地理解和参与赛马活动。
一、数据收集与预处理
1、数据来源
- 官方赛事记录:包括过去几年的新澳赛事成绩、马匹表现、骑师信息等。
- 第三方数据库:如Equibase、Race Results等,提供详细的赛事统计和分析报告。
- 社交媒体和论坛:收集专家意见和公众讨论,了解市场情绪和热门话题。
2、数据清洗
- 去除异常值:剔除明显不符合实际情况的数据点,如极端天气条件下的比赛成绩。
- 填补缺失值:对于部分缺失的数据,采用均值填充或插值法进行补充。
- 标准化处理:将不同量纲的数据转换为统一标准,便于后续分析。
3、特征工程
- 提取关键特征:如马匹年龄、体重、性别、训练师、骑师经验等。
- 构建衍生变量:根据马匹的历史表现计算其平均速度、加速度等指标。
- 编码分类变量:将非数值型的特征(如性别、场地类型)转化为数值形式。
二、模型选择与训练
1、回归模型
- 线性回归:适用于简单的关系预测,但可能无法捕捉复杂的非线性模式。
- 多项式回归:通过增加高次项来拟合更复杂的曲线,提高预测精度。
- 岭回归和Lasso回归:用于处理多重共线性问题,避免过拟合。
2、分类模型
- 逻辑回归:适用于二分类问题,如预测某匹马是否获胜。
- 决策树和支持向量机(SVM):适合处理多分类问题,具有较强的泛化能力。
- 随机森林和梯度提升机(GBM):集成学习方法,能够有效应对高维数据和复杂关系。
3、时间序列模型
- ARMA/ARIMA模型:自回归移动平均模型,适用于平稳时间序列的预测。
- LSTM神经网络:长短期记忆网络,擅长处理具有时序依赖性的数据。
- Facebook Prophet:专门用于节假日效应的时间序列预测工具,适用于周期性较强的数据。
4、集成学习
- Bagging和Boosting:通过组合多个弱学习器来提高整体性能。
- Stacking:将不同模型的输出作为输入,进一步优化预测结果。
- Voting:在分类任务中,通过投票机制综合多个模型的预测结果。
三、模型评估与调优
1、交叉验证
- K折交叉验证:将数据集分为K个子集,每次使用其中一个子集作为测试集,其余作为训练集,重复K次,取平均值作为最终评估指标。
- 留一法交叉验证:每次留下一个样本作为测试集,其余样本作为训练集,适用于小样本数据集。
2、性能指标
- 准确率(Accuracy):正确预测的比例。
- 精确率(Precision):真正例占所有正例的比例。
- 召回率(Recall):真正例占所有实际正例的比例。
- F1分数(F1 Score):精确率和召回率的调和平均数。
- AUC-ROC曲线:衡量模型区分正负样本的能力。

3、超参数调优
- 网格搜索(Grid Search):遍历所有可能的参数组合,找到最优解。
- 随机搜索(Random Search):从参数空间中随机采样,减少计算量。
- Bayesian优化:利用概率模型指导搜索过程,更快地找到最优参数。
四、结果解读与应用
1、胜负预测
- 根据模型输出的概率值,判断各匹马的胜算大小。
- 结合赔率信息,计算期望收益,辅助投注决策。
2、趋势分析
- 观察不同时间段内马匹的表现变化,识别潜在的规律。
- 分析特定条件下(如特定赛道、天气状况)的胜负倾向。
3、风险管理
- 评估模型的不确定性,设定止损点和止盈点。
- 分散投资,避免过度集中在单一马匹或赛事上。
五、案例研究与实战演练
1、历史赛事回顾
- 选取几场具有代表性的赛事,回顾当时的赛事条件和结果。
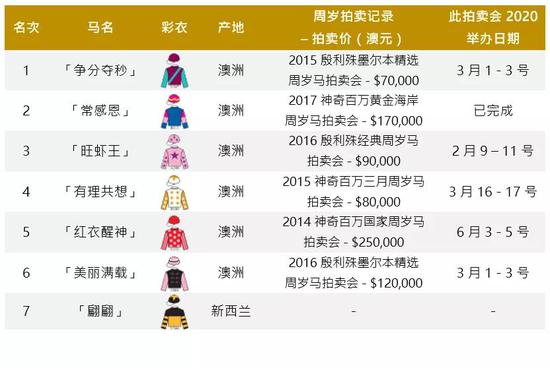
- 应用上述模型进行模拟预测,对比实际结果,检验模型的准确性。
2、模拟投注实验
- 设计一系列虚拟投注方案,基于模型预测进行操作。
- 记录每次投注的盈亏情况,评估长期收益率。
3、专家访谈与交流
- 邀请业内专家分享他们对赛马的看法和经验。
- 组织线上研讨会,与其他爱好者交流心得体会。
六、结论与展望
1、
- 回顾本文的主要发现和结论。
- 强调数据分析在赛马预测中的重要作用。
2、未来方向
- 探索更多先进的机器学习算法和技术,进一步提升预测精度。
- 结合心理学、生物学等领域的知识,全面理解赛马行为。
- 开发更加用户友好的分析工具,降低普通用户的使用门槛。
通过以上步骤,我们可以构建一个相对完善的赛马数据分析框架,帮助大家更好地把握新澳2024年的特马走势,任何预测都存在不确定性,实际操作中还需谨慎对待,希望本文能为您提供有价值的参考信息,祝您在新澳2024年的赛马活动中取得佳绩!







 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号